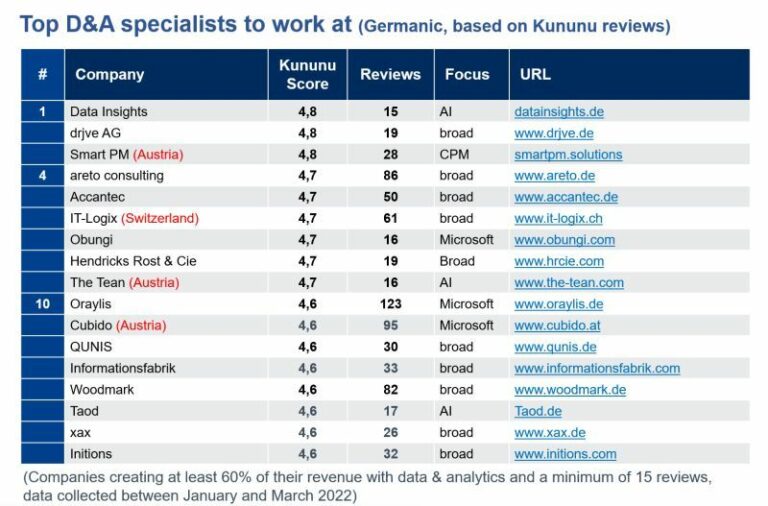
Ein Datenkatalog erstellt und pflegt ein Verzeichnis von Datenbeständen durch die Identifizierung, Beschreibung und Organisation von verteilten Datensätzen. Der Datenkatalog bietet einen Kontext, der es data stewards, data/business analysts, data engineers, data scientists und anderen line of business (LOB)-Datenkonsumenten ermöglicht, relevante Datensätze zu finden und zu verstehen und so geschäftlichen Nutzen daraus zu ziehen. Moderne durch maschinelles Lernen angereicherte Datenkataloge automatisieren verschiedene langwierige Aufgaben, die bei der Datenkatalogisierung anfallen, einschließlich der Metadatensuche, -aufnahme, -übersetzung, -anreicherung und der Erstellung semantischer Beziehungen zwischen Metadaten. Solche Datenkataloge der nächsten Generation können daher Metadaten-Verwaltungsprojekte von Unternehmen vorantreiben, indem sie es den Benutzern ermöglichen, Metadaten zu verstehen, anzureichern und zu nutzen.
Datenkataloge vereinfachen die Metadaten-Verwaltungsaufgaben und stellen sicher, dass die Datenkonsumenten besser in der Lage sind, die ihnen zur Verfügung stehenden Daten optimal zu nutzen.