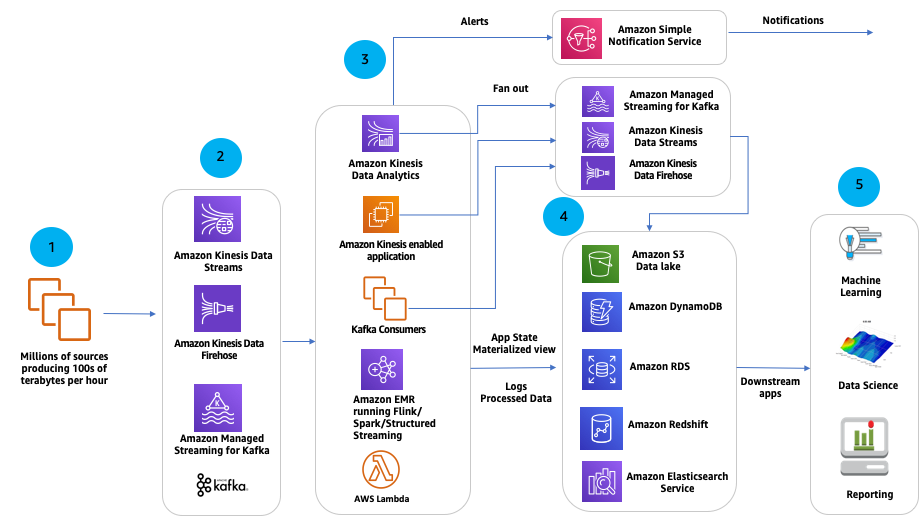
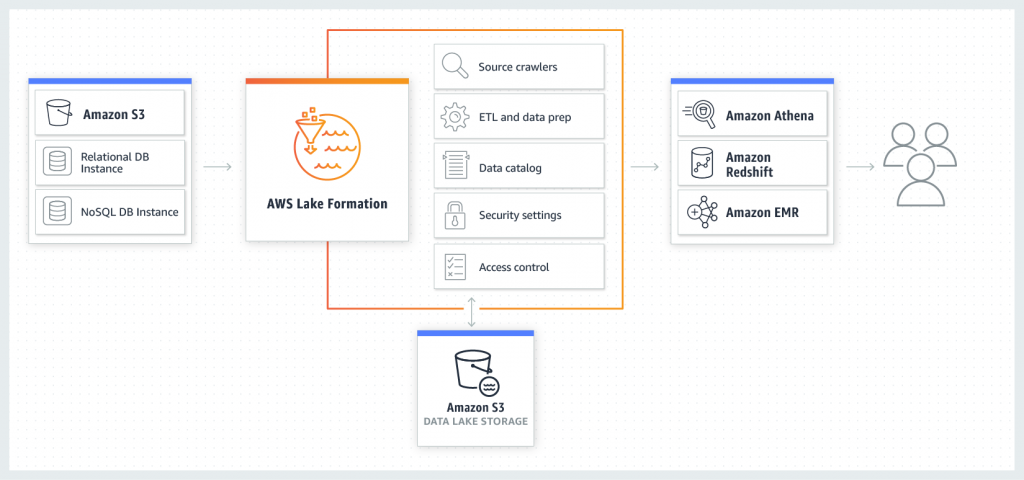
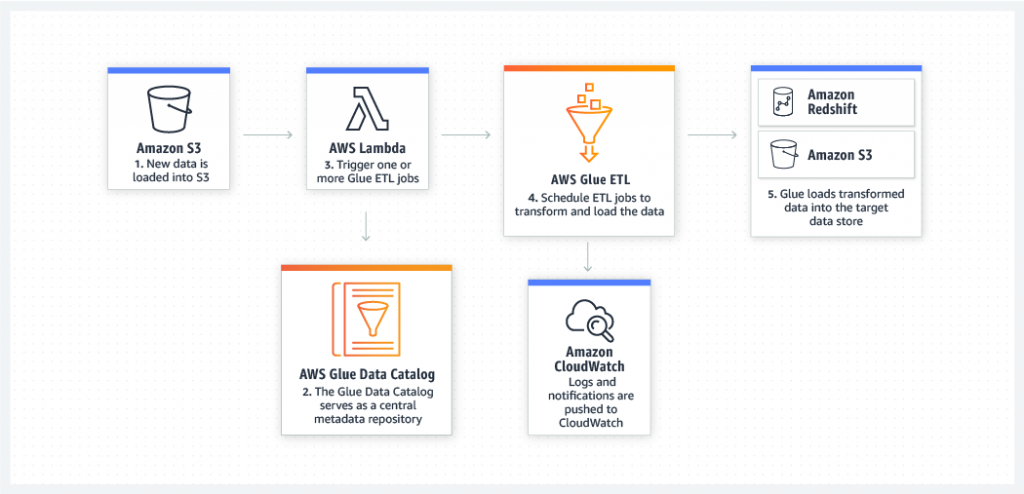
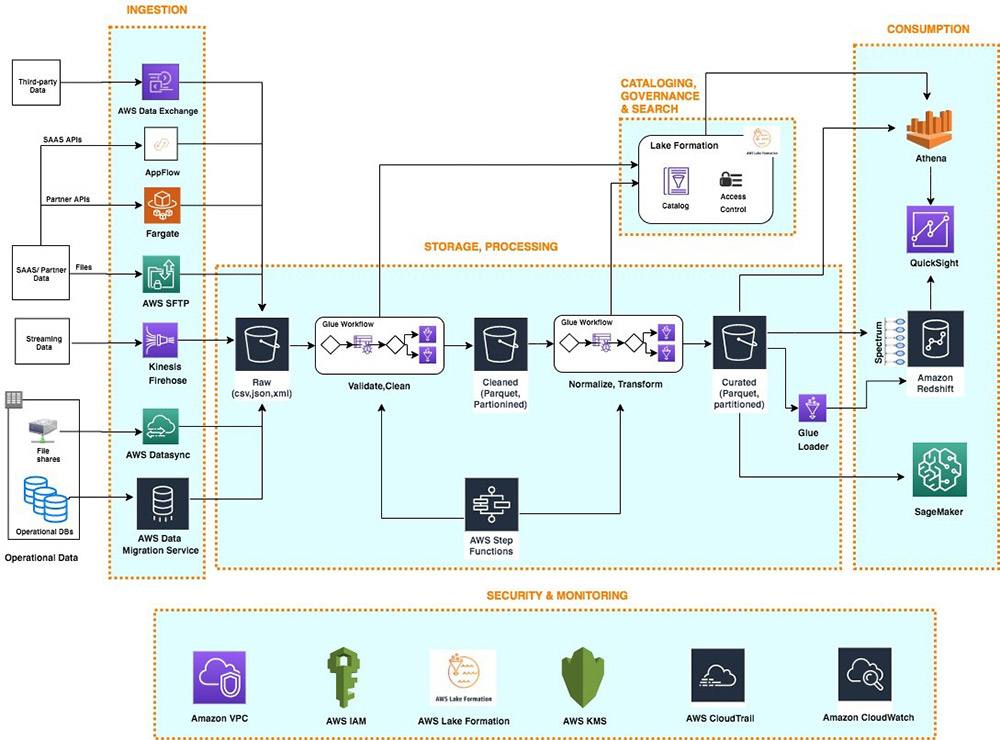
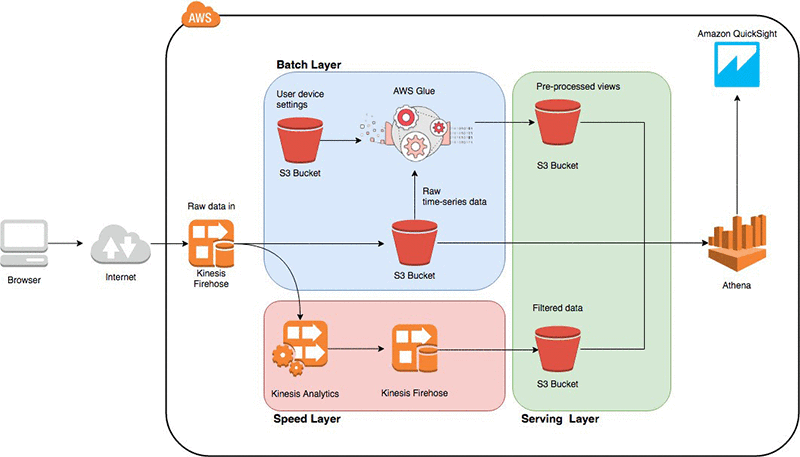
AWS Glue ist ein serverloser Datenintegrationsdienst, der das Auffinden, Aufbereiten, das Kombinieren von Daten für Analysen, Machine Learning, eine Anwendungsentwicklung vereinfacht.
Datenintegration bezeichnet den Aufbereitungsprozess von Daten für Analyse, Machine Learning, Anwendungsentwicklung. Er involviert mehrere Aufgaben, wie das Auffinden sowie Extrahieren der Daten aus mehreren Quellen, das Anreichern, Bereinigen, Normalisieren, Kombinieren der Daten. Natürlich auch das Laden und Organisieren der Daten in Datenbanken, Data Warehouses, Data Lakes. Diese Aufgaben werden oft von unterschiedlichen Benutzertypen erledigt, welche unterschiedliche Produkte verwenden.
AWS Glue bietet sowohl visuelle als auch codebasierte Schnittstellen, um eine Datenintegration zu erleichtern. Benutzer*innen können Daten mit dem AWS Glue-Datenkatalog einfach auffinden und aufrufen. Data Engineers, ETL-Entwickler *innen (Extract, Transform, Load = extrahieren, übertragen, laden) können AWS Glue Studio verwenden, um ETL-Workflows mit wenigen Klicks visuell zu erstellen, auszuführen, zu überwachen. Data Analysts und Data Scientists verwenden AWS Glue DataBrew, um Daten visuell anzureichern, zu bereinigen, zu normalisieren, ohne Code zu schreiben. Mit AWS Glue Elastic Views verwenden Anwendungsentwickler*innen die gewohnte Structured Query Language (SQL), um Daten aus verschiedenen Speichern zu kombinieren, zu replizieren.