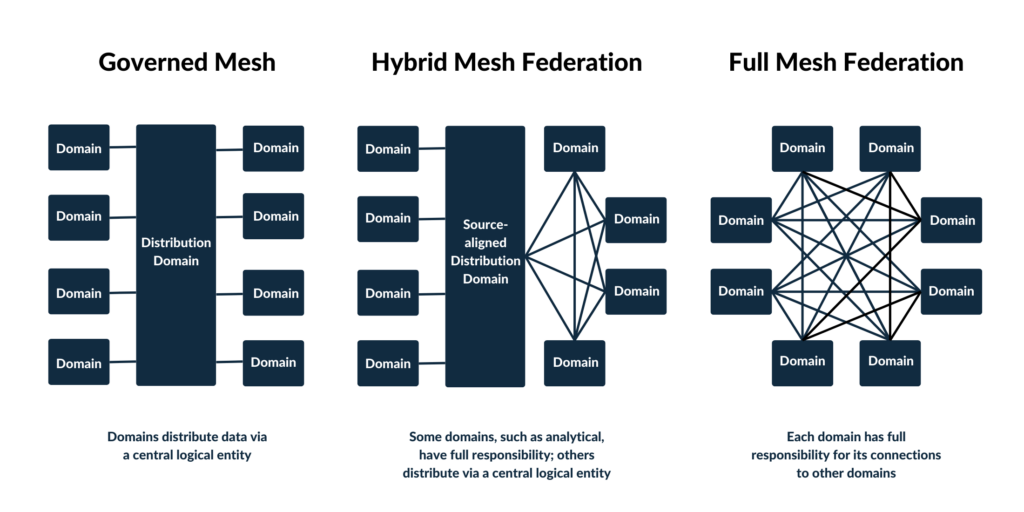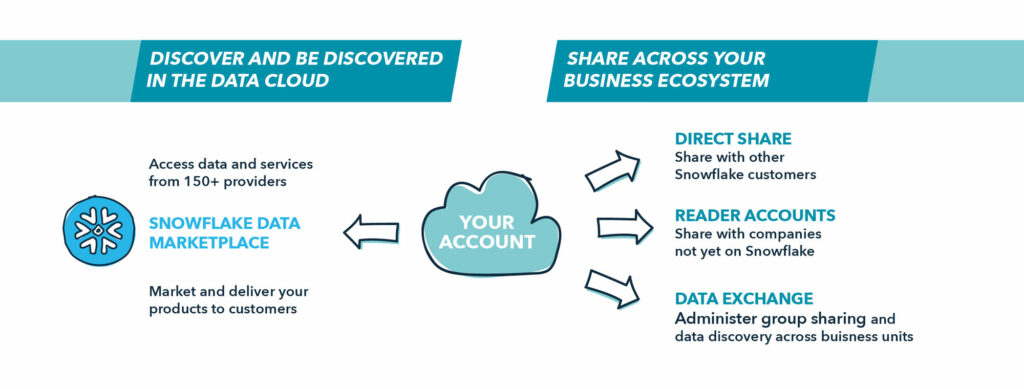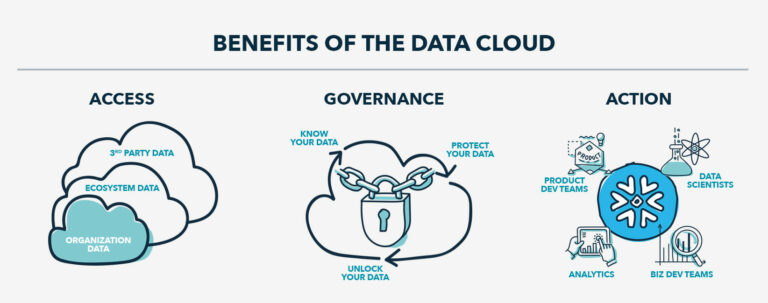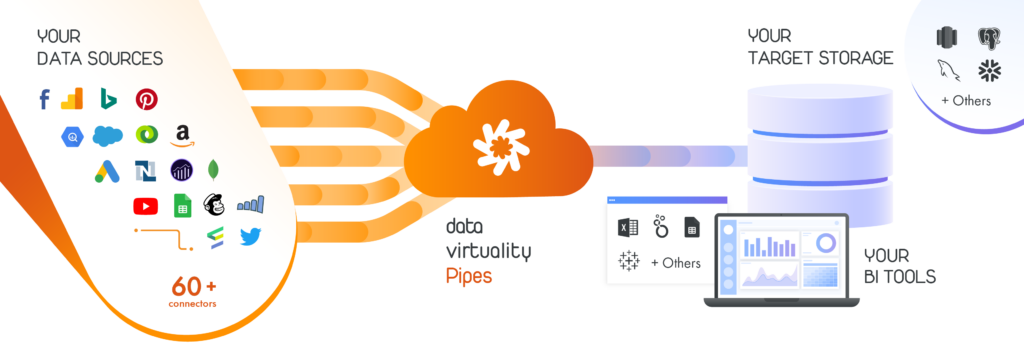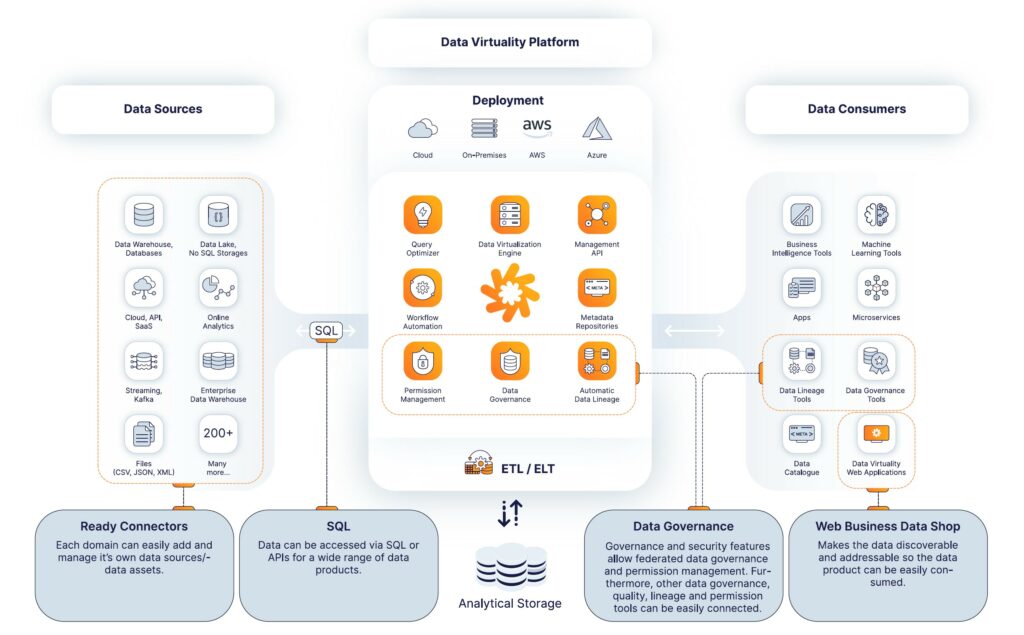
Die gespeicherten Daten können dann für verschiedene Bereiche dupliziert und in das Format gebracht werden, das für die jeweilige Verwendung geeignet ist. Dabei ist ein Umdenken von Nöten, weg von dem traditionellen Push- und Ingest ETL-Modell, hin zu einem Serving- und Pull-Modell für alle Unternehmensbereiche.
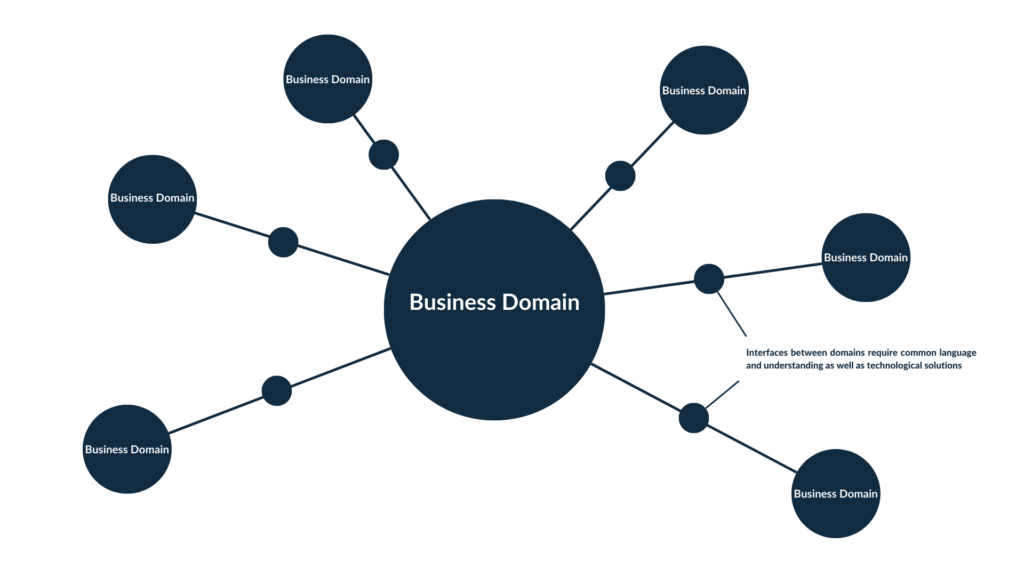
Der Grundgedanke ist, die Verwaltungsarchitektur und das Bestreben mit KI und Analytics einen Mehrwert aus vorhandenen Daten zu ziehen an die Komplexität von Organisationen anzupassen und skalierbar für die Zukunft zu machen.